
《科创板日报》4月13日讯(编辑 郑远方)当地时间4月12日,微软宣布开源DeepSpeed-Chat,帮助用户轻松训练类ChatGPT等大语言模型,人人都有望拥有专属ChatGPT。

开源地址:https://github.com/microsoft/DeepSpeed
OpenAI之前明确表示拒绝开源GPT-4,也收获了无数“OpenAI并不open”的吐槽。而AI开源社区已推出LLaMa、Vicuna、Alpaca等多个模型,帮助开发者开发类ChatGPT模型。
即便如此,现有解决方案下训练数千亿参数的最先进类ChatGPT模型依旧困难,主要瓶颈便在于缺乏RLHF训练普及——而微软本次开源的DeepSpeed-Chat,便补齐了最后这一块“短板”,帮助在模型训练中加入完整RLHF流程的系统框架。
仅需一个脚本,便可以完成RLHF训练的全部三个阶段,类ChatGPT大语言模型生成唾手可得,堪称“傻瓜式操作”。
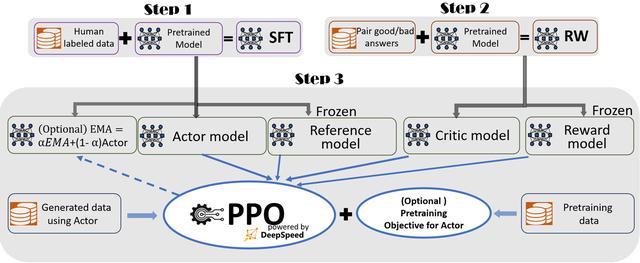
图|DeepSpeed-Chat的RLHF 训练流程图示,包含了一些可选择功能(来源:微软)
这还不是DeepSpeed-Chat唯一的优势,微软提供了中、英、日三语文档,作出了详细介绍。总体来说,其核心功能与性能包括:
1. 简化类ChatGPT模型训练、强化推理体验。
2. DeepSpeed-RLHF模块复刻了InstructGPT论文中的训练模式。同时,DeepSpeed将训练引擎与推理引擎共同整合到了一个统一混合引擎用于RLHF训练。
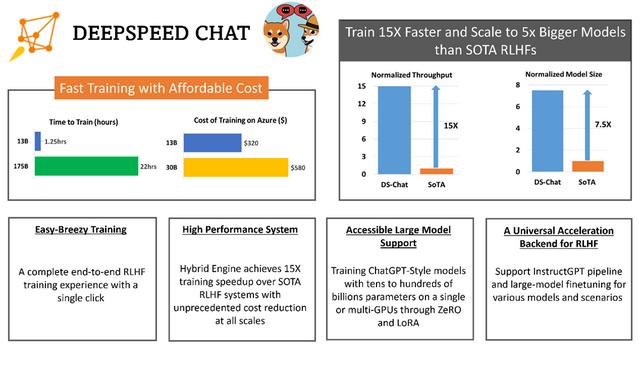
3. 高效性和经济性:可将训练速度提升15倍以上,并大幅度降低成本。例如,DeepSpeed-HE若在Azure云上训练一个OPT-30B模型,仅需18小时、花费不到300美元。
4. 卓越的扩展性:可支持训练数千亿参数模型,并在多节点多GPU系统上扩展性突出,只需1.25小时就可完成训练一个130亿参数模型。
5. 实现RLHF训练普及化:仅凭单个GPU,DeepSpeed-HE就能支持训练超过130亿参数的模型。因此无法使用多GPU系统的数据科学家和研究者,不仅能创建轻量级RLHF模型,还能创建大型且功能强大的模型。
此外,与Colossal-AI、HuggingFace等其他RLHF系统相比,DeepSpeed-RLHF在系统性能和模型可扩展性方面表现出色:
就吞吐量而言,DeepSpeed在单个GPU上的RLHF训练中实现10倍以上改进;多GPU设置中,则比Colossal-AI快6-19倍,比HuggingFace DDP快1.4-10.5倍。
就模型可扩展性而言,Colossal-AI可在单个GPU上运行最大1.3B的模型,在单个A100 40G 节点上运行6.7B的模型,而在相同的硬件上,DeepSpeed-HE可分别运行6.5B和50B模型,实现高达7.5倍提升。
因此,凭借超过一个数量级的更高吞吐量,DeepSpeed-RLHF比Colossal-AI、HuggingFace,可在相同时间预算下训练更大的actor模型,或以1/10的成本训练类似大小的模型
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/45421.html
相关推荐
-
胎儿过大、脐带绕颈,还能不能顺产?医生日常监测可避险
(声明:本文仅用于科普用途,为了保护患者隐私,以下内容里的相关信息已进行处理) 【基本信息】女,28岁 【疾病类型】脐带绕颈 【治疗医院】重庆医科大学附属第一医院 【治疗方案】孕妇…
-
女人之美
美,是一种综合因素,是一种素质状态值。女人的美:在于容颜、体态与气质。 女人的可爱:在于温柔、善良与聪慧。作为精致的女人,不需求太过的奢华,简约就好。 女人姿态的美,是风格,姿势,…
-
毛主席谈认识论,这12句话要收藏起来,慢慢细读
1963年5月10日至12日。 毛主席在审阅修改《关于目前农村工作中若干问题的决定(草案)》稿时,加写了一段具有前言性质的批语。 其中,大部分内容都讲到认识论问题,节选部分干货如下…
-
个人手机彩铃怎么设置(个人设置彩铃怎么设置)?
个人手机彩铃怎么设置(个人设置彩铃怎么设置)? 个人手机彩铃的设置方法有很多种,下面我将为您介绍几种常见的设置方式。 1. 使用手机自带的彩铃设置功能:大部分手机都内置了彩铃设置功…
-
开封新东方村镇银行(宋小睿一般考多少分)
宋小睿一般考多少分?开封新东方村镇银行 东京梦华录,此东京非日本的东京,而是北宋都城,也就是现在的河南开封。如果你生活在北宋的东京,那一定很幸福。对于北宋普通老百姓而言,都城东京就…
-
降价引发大规模争议,4月投诉最多的10款新能源车,有你的车吗?
4月份刚刚过去,新能源汽车销量逐步公布的同时,新能源汽车投诉排行榜也出炉了。 那么,有哪些新能源车“光荣上榜”呢? 别着急,我们已经为各位朋友筛选了4月份投诉最多的10款新能源车。…
-
每天洗脸的时候到底要不要使用洁面乳?
早上洗脸的时候到底要不要用洁面乳? 肌肤在夜间并没有接触到外面的脏空气,所以早上使用清水洗脸就可以了吗?并不是!即使整晚都呆在室内,但肌肤内部仍有皮脂在不断分泌,同时,肌肤在前一晚…
-
审计在公司治理中作用,审计是干嘛的工资高吗
内容提要:建立和完善公司治理结构是当前我国深化国有企业改革、建立现代企业制度的一项重要任务。其成功与否,在很大程度上取决于能否设计出一整套制度来对其进行规范和制约。审计作为公司治理…
-
古代牧羊犬市场价格?多少钱一只??秋田犬多少钱一只!
狗若爱你,就会永远爱你,不论你做了什么事,发生什么事,经历了多少时光。 古代牧羊犬温顺随和,憨厚、可靠、值得信任,没有无谓的神经质或者攻击性,可以照料儿童。样子像大型毛绒玩具,十分…
-
撩中年女人,做到“三个主动”,很好搞定!
撩中年女人,是一门需要技巧的艺术。中年女人对于感情的需求与年轻女孩不同,需要更多的关心与温暖。下面,本人分享一下如何做到“三个主动”,来帮助您很好地搞定撩中年女人的问题。 一、心理…