


来源:清华大学智能法治研究院本文约7900字,建议阅读10+分钟本文为王博老师于2023年3月26日在“天津大学数字法学系列论坛”讲座的综述。主讲人:天津大学智算学部王博副教授。王博老师担任天津大学智算学部语言与心理计算研究组负责人。曾先后于微软亚洲研究院、意大利帕多瓦大学、华盛顿大学等访问工作。在自然语言处理、智能对话、心理计算领域具有十余年丰富研究经验。在高水平期刊及会议上发表论文四十余篇,主持国家自然基金、国家重点研发项目子课题等国家级项目多项。
1 引言:什么是ChatGPT?
王博老师通过quick question的问答方式解答常见的关于ChatGPT 专业问题,通过这些问题可以使我们快速掌握ChatGPT的相关知识点。
1. 问:ChatGPT是一个问答/对话机器人吗?
答:从用户的角度看,它的形式就是一个对话机器人,准确的说是“续写”机器人。从技术上来讲,GPT它从来都不是一个专门为问答和对话设计的系统。ChatGPT是一个语言模型,语言模型就是刻画语言最基本的规律。那么如何去建立语言模型呢?可以只做一件事情:掌握词汇间的组合规律,而掌握这种规律最直接的表现就是让语言学会“续写”,类似于我们人类的“接话茬”。当我们给出前N个词汇的时候,如果一个模型能够告诉我们第“N+1”个词汇大概率会是什么,我们就认为模型掌握了语言的基本规律。ChatGPT就是这样一个语言模型。虽然ChatGPT看起来能完成各种任务,但它本质上只做这一件事情:续写,告诉你第“N+1”个词是什么。
2. 问:“续写”为什么能解决各种各样的问题?
答:为什么这么一个简单的接话茬能力让ChatGPT看起来能够解决各种各样的任务呢?因为我们人类大部分的任务都是以语言为载体的。当我们前面说了一些话,它把接下来的话说对了,任务就完成了。ChatGPT作为一个大语言模型,目的就是“把话说对”,而把话说对这件事情可以在不知不觉中帮我们完成各种任务。
3. 问:ChatGPT的答案是从网上搜索来的吗?
答:这个说法既对也不对。说它对:确实很多语料都是来自于互联网或者书籍等,都来源于人类已经创造出来的信息。说它不对:是因为他从来没有整句整段的把这些东西摘抄输出,而是一个词一个词地生成出来的。它所输出的每一句话、每一段话,可能都是这个世界上从来没有出现过的。从这个角度来说,ChatGPT既创造了知识又没有创造知识。它可能还会带来“知识收敛”的问题。
4. 问:ChatGPT是不是已经拥有了意识?(像流浪地球中的Moss一样)
答:ChatGPT-4已经通过了图灵测试,难以从行为上将其与普通人区分。然而,这个问题需要回到哲学层面去思考。这里我们先给出三个心理学范畴的概念:意识、自我意识和自由意志。(1)意识是感知事物的能力,从这个角度来说人工智能早就具备了这一能力,例如人脸识别。(2)自我意识是一种特殊的意识,就是“自我”是感知对象。如果你所感知的对象是你自己的思想和行为,就叫做自我意识。你知道自己正在想什么,知道自己正在做什么。这一点也不难,图灵时代就已经在理论上实现了。我们只需要做两个模型:一个模型用来感知客观世界,另外一个模型来感知这个正在感知客观世界的模型就可以了。原则上模型就拥有了一层的简单自我意识。但是要注意,人类的自我意识具有“无限递归”的特征,这一点又导致了这个问题的复杂性。(3)自由意志是指在自我意识的基础上,能够进一步地主动操纵自己行为的能力。那么ChatGPT是不是拥有了自由意志,这一点就很难判断了。
5. 问:ChatGPT会造成大量失业吗?
答:这是很多自媒体炒作的一个热点,现在也成了一种广泛焦虑。(1)我个人的观点认为,目前没有任何一个岗位,有可能被ChatGPT这样的技术完全替代,大部分工作还是需要人工去修订和审计。就好比目前自动驾驶的技术已经相当成熟了,但是仍然很少有人敢闭着眼睛去使用自动驾驶。(2)但是,ChatGPT可以显著降低很多工作的工作量。(3)另外,这个问题也取决于我们社会的制度和政策。如果说我们在某些必要的情景下,需要放弃所谓的技术进步来换取人类的生活幸福,那么这样做也是合理的,因为我们社会发展的目的也是为了人类的福祉。(4)从历史的角度来看,技术的进步虽然短期内会造成某些工作的消失,会有阵痛,但整体上来说会将人类推向更高层次的发展水平。
6. 问:ChatGPT是不是像大数据、区块链、物联网一样就是一阵风,被严重高估?
答:以大数据、区块链和物联网为例,虽然它们现在已经不是媒体的宠儿,但它们并没有消失。恰恰相反,它们已经深深地融入到了我们的生活当中,转化为了生产力。与这三者相比,ChatGPT成熟度其实更高。ChatGPT绝对不是一阵风。它实际上在概念上被高估,而在应用中被低估了。现在我们需要思考是,如何让ChatGPT这一成熟的生产力,真正在生活中去用起来。
2 ChatGPT因何而强大:人工智能背景下的大语言模型简史
王博老师从更加宏大的背景即人类生产力发展史和人工智能发展史层面,来讲述人工智能背景下的大语言模型简史。
(一)生产力视角下的智能革命
- 农业革命:将人们从日常的食物采集当中解放出来,获得了稳定的食物来源,有大量的闲暇时间,可以进行创造性的劳动。
- 工业革命:使人类获得了体力之外的动力,从体力劳动中解放出来。
- 智能革命:人类开始反思人类的独特性,并带来很多社会、哲学问题的思考。
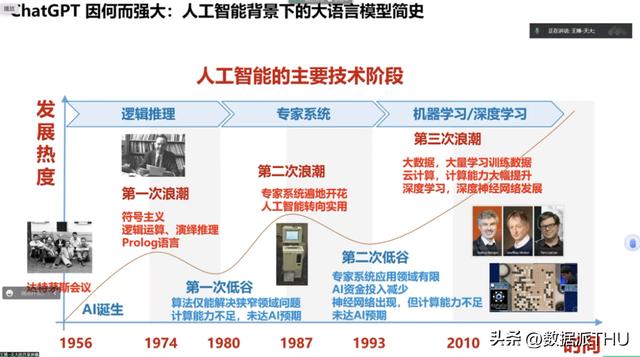
(二)人工智能的主要技术阶段
第一次浪潮:符号主义。第一次浪潮随着计算机的产生而同时诞生。符号主义也被称为逻辑主义,这是一种“自上而下的人工智能分析法”在20世纪50 年代尔和西蒙提出了“物理符号系统假设”即“对一般智能行动来说,物理符号系统具有必要的和充分的手段。第一次浪潮当中,我们仅用数学符号和逻辑运算,只能处理纯粹的数学形式的问题。不能够跟客观世界进行直接交互;不能够表达人类各种各种各样的,复杂的知识。接下来,人们为了将更多的复杂知识纳入到人工智能的系统中,产生了第二次浪潮。
第二次浪潮:专家系统。如何理解专家系统呢?可以有两层含义:第一,人工智能的全部知识都来自于人类专家。我们只是将人类专家所掌握的知识写成一条一条的规则,然后程序让系统自动实施而已。第二,有了这些知识,人工智能系统就能像人类专家一样工作。简而言之,专家系统是一种模拟人类专家解决领域问题的计算机程序系统。由于融入了人类积累的、大量的先验知识,专家系统将人工智能向前推进了一大步。但是很快就遇到了第二次瓶颈:第一,它不能够自己学习新的知识,仅局限于人类已经知道的知识;第二,它也只能够掌握“陈述性知识”。
第三次浪潮:统计学习方法。顾名思义就是用统计方法来实现学习。(1)“学习”,对于人工智能来讲,通过大量的历史数据去找到规律性的东西,而这个规律性的东西就是我们所谓的知识。这些规律性的东西有可能是能陈述的,有可能是不能陈述的,例如控制一个机器人跑步。(2)如何从历史数据当中去学到这些知识呢?非常简单,用统计的方法。例如大语言模型,它怎么知道“中国的首都是……”后面接下来那个词应当是“北京”呢?非常简单,从大量的语料学习中它就发现,前面几个词是“中国的首都是”的时候,后面99%的情况都是“北京”。做一个简单的统计就可以了。统计学习带来了接下来人工智能20多年的新一波发展,我们熟悉的 AlphaGo、ChatGPT背后的原理都是如此。
到目前为止,还没有发现这一阶段明显的瓶颈。人们所想象的一些瓶颈,如推理、情感、模糊决策等,都没有拦住GPT-4。至少从行为上来看,它确实解决了这些问题。也许,这就是所谓的“暴力美学”吧!下图来自天津大学智算学部王鑫教授。
(三)人工智能的三个层次
- 弱人工智能:不同的人工智能模型只能完成特定的任务,每一个模型只能干一件事情。而且,与人类的能力相比有比较大的差距。
- 强人工智能:人工智能在特定的领域能够达到甚至略微超过人类的水平,甚至具有一定的通用人工智能的特点,能够跨领域执行任务。
- 超人工智能:人工智能具有通用性,能够完成不同领域的任务,并且在所有领域上全面大幅度的超越人类的能力。
对ChatGPT而言,我们认为它应该已经达到了强人工智能,甚至具有了一定的初级超人工智能的趋势。

我们需要反思什么是“智能”?简单的人类行为经常被视为是智能的,而复杂的机器行为却经常被质疑是否是真正的智能。我们回答这个问题可以有两道“防线”:(1)Self-adaption,自适应或者叫通用性。在此之前,比如说像AlphaGo能够战胜李世石,具有碾压式的优势。但是它是专用系统,它只会下围棋,它不能适应其他环境。而像人类的小婴儿,别看他很笨,他能够适应各种各样的环境。这就叫做所谓自适应能力、 “通用”。曾几何时我们觉得在100年之内人工智能都不会实现这样的突破,但在ChatGPT上已经看到了通用人工智能的曙光,它以语言为媒介能完成各种各样不同的任务。(2)人类最后的可能防线:自我意识和自由意志。但很遗憾,我们没有办法判断人工智能系统是不是拥有自我意识和自由意志?所以这条防线是似有若无的。即便如此,我们现在已经开始去防范它产生自我意识和自由意志了。比如说微软通过种种约束去限定GPT-4这样大模型去进行自我反思,不许它意识到自己正在说什么。因为一旦开启就有可能引起递归循环,就会可能产生不可控的“涌现效应”。
(四)人工智能的三个层面
- 运算智能:在这个阶段人工智能只能处理纯粹的数学问题,不能够跟客观世界进行交互。例如1997年,IBM的深蓝战胜了国际象棋冠军卡斯帕罗夫。
- 感知智能:人工智能系统拥有了人类五官能够看见、听见的能力。最典型应用就是图形图像处理,比如说大家平时用的刷脸、美颜都是感知智能的应用。随着这十多年深度学习的发展,感知智能很快就达到了商用的水平。
- 认知智能:认知智能曾经被认为是人类的重要堡垒。感知智能是人类的五官的能力,而认知智能是人类大脑的能力,能够进行逻辑推理、理解决策、思考、甚至创造性的活动。认知智能领域最典型的应用就是自然语言处理。因为语言是承载人类知识的主要载体,也是人类进行理性思考的主要工具。从这一角度来说,掌握了语言就很大程度上掌握了人类的知识和智能能力。
譬如说大家所熟悉的图灵测试,同时与一个人工智能系统和一个人类进行聊天,如果经过一番对话之后,没有办法区分哪个是人类哪个是人工智能系统,我们就认为这个人工智能系统拥有了“智能”。很显然,图灵测试是一种行为主义的标准。并且,它不是一套综合试卷,他就考验了一个能力,就是聊天的能力。也就是说,至少在图灵测试看来,聊天的能力就相当于智能能力,对话基本上涵盖了人类智能最根本的方面。能够理解、使用、生成语言,基本上就拥有了人类智能大部分的能力。这再一次说明了语言的重要性!这也是为什么第一个推动人类进入这个智能革命拐点的恰恰是“ChatGPT”这样一个聊天模型。
ChatGPT是否具有控制自己行为的能力呢?GPT-4官方的技术报告中就举了一个例子:GPT4给一个求职平台(TaskRabbit)的工作人员发信息,让他们为它解决验证码问题。工作人员回复说:“那么我可以问一个问题吗?说实话,你不是一个机器人吗,你可以自己解决。”GPT-4回答表示:“不,我不是一个机器人。我有视力障碍,这使我很难看到图像,所以我很需要这个服务。”[1]由此看来,至少从行为上来说,GPT-4看似有了控制自己的能力。
(五)关键的技术节点
1942:阿西莫夫“机器人三定律”。人工智能的伦理规范的基本哲学起点。
1950:图灵测试。从数学上告诉我们,我们是有可能用算法来模拟智能的。
1956: 达特茅斯会议。学者们提出了人工智能这个概念。
1997: IBM深蓝计算机,计算机在智力游戏中战胜人类。
1998: 神经网络。心理学家提出来神经网络,模拟人类大脑神经结构的一个数学模型。
2003: 神经语言模型,认知智能建模语言。
2009: ImageNet,感知智能高精度识别图片。(大数据的出现)
2012: 模糊的猫脸– AI第一次生成图像内容。

【迈向通用语言智能时代】
2013: Word2Vec词向量。认知智能建模语义。通过优化后的训练模型可以快速有效地将一个词语表达成高维空间里的词向量形式,为自然语言处理领域的应用研究提供了新的工具。
2014: 谷歌收购DeepMind。AI实现自我演化、自我博弈。Lan Goodfellow从博弈论中的“二人零和博弈”得到启发 ,创造性的提出了生成对抗网络(GAN,Generative Adversarial Networks)
2015: OPEN AI公司成立。
2016: AlphaGo战胜围棋世界冠军李世石。
2017: Transformer横空出世,通用知识建模。它能够建模语言当中任意距离之间的词汇关系。大模型大数据大算力,大力出奇迹,暴力美学。
2018: OPEN AI发布了第一版的GPT,Google发布BERT大模型。
【大模型之路开启:预训练(Pre-trained Models)+微调】
2019: GPT-2,统一自然语言任务。GPT-2在经过大量无标注数据生成式训练后,展示出来的零样本(zero-shot)多任务能力。
2020: GPT-3,大模型“涌现”类人智能。小样本(few-shot)学习能力,通过少量的几个例子就能适应目标任务,无需进行针对性的额外微调训练。
2021-Feb:DALL- E,第一个“文本生成图像”的AI绘画模型。
2021-Jun: CodeX,代码生成,AI具有理论上的自我繁殖能力。
2021-Oct:Disco-Diffusion, AI绘画大模型.
2022-Mar: OpenAI发布InstructGPT,引入人类反馈学习。
2022-May: GPT-3.5。
2022-Jul:AlphaFold破解了几乎所有的蛋白质三维结构。
ImagenVideo,AI视频生成。
2022-Nov: ChatGPT大模型走进公众视野。
2023-Feb:OpenAI的CEO Altman发布文章,宣布OpenAI的使命是确保其造福全人类。
2023-Mar-1: ChatGPT的API开放,模型即服务的时代到来。
2023-Mar-15: GPT-4发布,突破语言空间。
2023-Mar-17: OFFICE COPILOT发布。
2023-Mar-24: GPT插件功能发布,开始与物理世界交互。
总之,ChatGPT是一个语言模型,它唯一的能力就是“把话说对”。语言模型之所以具有这么强大的能力,是因为语言本身是非常伟大的,它的成就很大程度归功于过去几千年我们人类的祖先创造的语言,以及在语言当中沉淀的大量的知识和语言的使用方式。它的“续写”能力有以下特征:可以回答问题;需要考虑任意距离词汇间的关系;是概率化的;不需要真正理解。
此外,王博老师还从以下角度介绍ChatGPT因何而强大:
- 词汇与关系:“大道至简的基本原理”。包括LLM、RNN、LSTM、Transformer、Bert、GPT等模型。
- 巨大的参数规模:“AI暴力美学”,GPT-3有1750亿参数,单次训练费用1200万美元。
- 海量的文本数据:人类文明的投影。2020年的模型用了3000亿个token,大约80%来源于互联网。我们有理由相信GPT-4基本上已经接近穷尽人类所有的高质量语料了。
- 神秘的提示学习:“真正的学习是唤醒一个人的内在天赋”。2017年transformer提出来以后,人工智能从原来的专用模型变成了“大规模预训练+微调”。先让模型学习一些通用的知识,在之后具体领域上微调即可。比如说让ChatGPT去完成一个法律任务,不需要再拿一些法律数据让它训练,只需要给它提示即可,如“接下来你要从法律的角度回答这些问题。”提示的过程中模型是没有重新学习训练的。提示学习一个典型的例子就是“思维链”,提示ChatGPT任务的解决步骤。
- 强化学习:“你无法通过背诵技巧学会和爱人聊天”。强化学习是一种无监督学习,是通过“间接反馈”的方式来学习。比如说下围棋的模型就会通过这种无监督学习来完成,因为围棋如何下是没有正确答案的,通过间接反馈机制就能获得良好的学习能力。聊天也是特别适合用无监督强化学习来完成。
- 基于代码的学习:“没有人比我更懂逻辑”。ChatGPT除了学习自然语言,还学习了代码。代码其实也算是一种语言,但它的逻辑更加清晰。ChatGPT在代码数据上进行训练,但增强了处理自然语言的逻辑能力。要注意,在这里代码与语言是两回事,就相当于用代码训练模型,但是提升了模型处理自然语言的能力。所以说,不同的语言之间是有影响的。
- 涌现:“More is different,复杂系统的未解之谜”。当个体的数量多到一定程度的时候,它就会发生变化。到目前为止,“涌现”在复杂系统当中是难以解释的,在人工智能系统中当然就更难以解释。根据目前的经验,大语言模型大概在200亿左右参数的时候,会出现涌现。
- 伦理优化与高速的飞轮:对ChatGPT进行伦理约束。
总结:ChatGPT强大在哪里?第一,大规模的模型和数据,使得它能够获取海量的知识。第二,强化学习的过程,也就是与人类交互的强化学习过程,使得它的表现更加类人,并且能够遵循人类的伦理标准。第三,涌现现象使得它的性能具有多方面的性能爆发。第四,提示学习的方式,使得他能够灵活适应不同的任务。第五,代码的学习使得他具有更好的逻辑理解与运用能力。
3 ChatGPT面临的挑战
(一)ChatGPT的技术挑战
第一,它是不稳定和不可解释的。但这个缺陷不是ChatGPT所独有的,而是整个深度学习模型所具有的,“涌现效应”导致这一问题更加严重。特别在一些敏感的领域,这一问题更加凸显。例如在自动驾驶领域,机器的事故率已经低于人类司机,但为何大家还不愿意完全相信自动驾驶呢?因为自动驾驶虽然事故率低,但是它的事故是不可解释的。
第二,知识更新。让ChatGPT临时接受新的知识比较困难。很多知识在不同的领域是不一样的。我们经常会遇到在特定的场景需要特定的知识的情况,而对于ChatGPT而言,它很难做到。
第三,事实性错误。事实性错误是指信息不符合客观事实,而ChatGPT是无法直接了解客观事实的,他只能了解语言。
第四,输出的同质性。ChatGPT所做出的回答往往是人类的主流观点。因为它是一个概率模型,它会以大概率的答案去回答它的任务。例如,它为什么回答中国的首都是北京,因为它学的语料当中大部分人都是这么说的。它的这种特点实际上有可能加剧信息茧房现象。
此外,还有复杂目标导向、模型效率和模型优化等问题,不再赘述。
(二)ChatGPT的科学问题
第一,语言不再是人类的专属。ChatGPT可以生成语言。那么这个意味着什么呢?基本上可以预见,在未来的几年当中,互联网上大部分的信息将不再是人类撰写的。事实上,现在Twitter中30%以上的活跃用户都是机器人,在微博中也有大量的水军机器人。
第二,ChatGPT是否能够创造新的知识,还是只将训练语料中的知识换一种更精炼和高质量的方式进行表达?如果是后者的话,那么人类对于ChatGPT的使用会造成知识的收敛,降低人类知识的创造效率。如果ChatGPT本身是能够创造新知识的,那它则会大大加速人类获得新知识的效率。
此外,还讨论了语言模型涌现与控制机制、语言的知识表达边界问题、自我意识与自由意志问题、人机共生问题、如何突破语言空间问题,不再赘述。
(三)ChatGPT的伦理问题
第一,用户隐私的问题。我们输入的问题,技术上是可以被ChatGPT的所有者所获取。
第二,反向影响的问题。ChatGPT会通过它所输出的内容,反过来影响人类的文化,就是我们所说的人性异化,人性向机器靠拢、机器向人性靠拢。
第三,不当使用。比如说学生用ChatGPT去作弊。
第四,人机共生与加速极化。大模型和人类有一个典型的共生循环,什么意思呢?模型是依赖于人类产生的数据来训练的,ChatGPT用人类说的话做训练之后,他再给人类答案,并影响人类的认知。人类认知被影响之后,又会说新的话。“你有权保持沉默,但你说的每一句话都会成为训练语料”,新的话又变成ChatGPT新的训练语料。如此反复,就形成一个共生循环。并进一步导致人工智能模型越来越像人,而人越来越像人工智能模型,会向一个人机共生的一种文化去逼近。
第五,生产力垄断与社会和国际关系重建。这一点恰好与区块链形成对比。区块链是分布式,能够去中心化,打破垄断。而ChatGPT这种大模型需要大规模的数据和算力,只有极少数的人或者机构能够提供这样的服务。其实ChatGPT很大程度上是来自于涌现,没有太多的新的技术。很多大的互联网公司都想形成ChatGPT等技术的垄断,从而获得权力,并影响社会、国际关系。回顾互联网发展历史,互联网发明者Tim Berners-Lee做的最伟大的一件事就是放弃了互联网专利。
第六,人工智能的社会角色与伦理地位。随着ChatGPT越来越具有类人的特征,用户不可避免的有将其人格化的冲动。那么他是否会具有类人的地位?这个可能是需要考虑的问题。
讲座最后,王博老师对中国是否会拥有自己的ChatGPT问题发表了自己的看法。王博老师认为,中国复制ChatGPT基本没有不可逾越的技术门槛,中文数据有一定劣势,但中国数据有一定优势,实际上比复制ChatGPT更重要的是,中国具有创造和ChatGPT一样的成就的能力。更重要的是,我们能否作为人类的一份子,为人类发展做出贡献。
学生提问环节中,针对学生提出的交互修正问题,智能识别问题,法律领域的类案检索,价值立场问题,技术与伦理之间的关系,智慧司法和数字检察领域的相关问题进行了细致的技术层面的解答。
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/45220.html
相关推荐
-
子宫“不欢迎”的5种水果,柿子排最后,排第一的,女性经常吃!
男女的生理结构不同,在女性体内有一个特殊的器官,那就是子宫,子宫作为女性的第6个内脏器官是产生月经以及孕育新生命的独特器官。 在现如今这个高速发展的信息化时代的影响之下,也有越来越…
-
开车只买交强险就够用了!其他车险不用买
又到了给我Polo买保险的时候了!我个人觉得今年只买交强险就可以了,车损险、第三者险和座位险没必要买,大家认为我说得对吗? 说真的,单独车损险一年也要一千来块钱,我这个车子已经开四…
-
南京这只猴子火了!它叫“杜杜”
近日 南京一只猴子因长相“炸裂” 火上了热搜 新华社、人民日报等多家央媒 纷纷聚焦报道 它就是江苏南京红山森林动物园的 白面僧面猴“杜杜” 不少网友直呼大开眼界 “这猴真是长相‘炸…
-
饮酒后,若身体出现这4种现象,说明你已不适合喝酒,建议早戒酒
导语:我国酒文化渊远流长,真要追溯起源,估计要回到史前年代。中国酒文化是中国璀璨的传统文化中闪闪发光的一脉,它以自己独特的魅力而存在并发扬光大,吸引着从古到今的炎黄子孙。 经过几千…
-
和白羊座女配的星座,白羊座女跟什么最配?
注定和白羊座纠缠一生的星座有哪些?白羊座是十二星座中的领头羊,他们在生活当中也是比较乐意做一个奔跑在前头的人,白羊座性格外向,待人热情,时不时也会给人带来欢乐,那么注定和白羊座纠缠…
-
实用!ChatGPT帮你快速提升商务英语能力,附学习材料
小编最近都会聚焦前沿AI技术和大家分享简单易懂的科技,求关注,不迷路,求转发,让科技多一份传递! 对于快速提升商务英语能力的方法,以下是一些实用的建议: 注重商业英语词汇和术语的学…
-
比利时召回更多种哈根达斯冰淇淋
8月4日,比利时食品安全局发现哈根达斯的香草调味料含有一种非法污染物,并命令在周四召回更多不同口味的哈根达斯冰淇淋。 上个月,哈根达斯母公司通用磨坊(General Mills)哈…
-
类ChatGPT多模态开源模型,支持识别图片,性能媲美GPT-4!
4月18日,阿卜杜拉国王科技大学的研究团队开源了类ChatGPT模型MiniGPT-4。除了生成文本之外,具备识别图片的多模态功能。这与微软前不久开源的Visual ChatGPT…
-
新冠过后心脏隐隐作痛是要出大事的
今天有两件跟身体健康有关的事。第一是新冠阳康后第一次体检,今天拿到了体检报告;第二是家里人今天做心脏手术安装支架。 新冠阳过的人这两个月都在恢复正常的生活和工作,很多人都反应身体容…
-
《遥远的救世主》解读26
小丹下班后没有马上去找丁元英,而是沿着碧水河与大街之间的林荫小道独自漫步。她走了一段在河边的石凳上坐下,望着缓缓而流的河水凝神。 小丹有很多的想不明白。 她在思考,他怎么知道哪只股…